One of our airhdl users recently asked how he could use an airhdl-generated register bank to initialize the 30,000 (or so) weights of a neural network circuit.
When dealing with such large numbers of coefficients, it’s not practical to create a dedicated addressable register for every coefficient as the corresponding logic becomes too large and and slow. What you can do instead is to either store them in a memory, which is very efficient in terms of logic resources, or in a register chain in case you need to concurrent access to the coefficients.
The memory option is quite straightforward as airhdl allows you to create memory-typed register map elements, which you can connect to a block memory components as shown in this article. The downside of this option is that you can only access one element at a time from the user logic.
In the register chain option, the coefficients are stored in the flip-flops of a large shift register, which gives you concurrent access to all of the elements. To implement the register chain, you will first need to create a write-only register (e.g. weight) with a value field corresponding to the width of your coefficients (e.g. 10 bits):

Consequently, the following user output ports are exposed in the generated RTL component:
weight_strobe | pulsed every time a new value is written to the weight register |
weight_value | the current value of the weight.value register field |
You then connect those ports to the input of a 30,000-deep shift register that is part of the user logic, with the weight_strobe acting as a clock-enable to the shift register. To initialize the shift register and thus your coefficients, all you have to do is write the 30,000 coefficients in a row over the AXI4 interface to the weight register using a fixed address pattern. Make sure not to use an incrementing address pattern as there is really only one adressable register in the register bank.
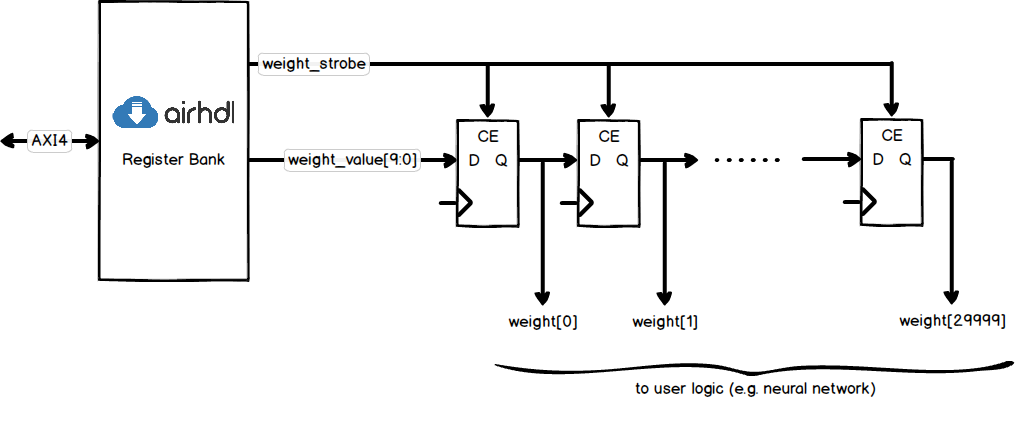
One issue you may run into while implementing this circuit is the high fanout on the weight_strobe signal, which can cause excessive delays and thus timing violations. Here are two ideas to improve the situation:
- Split the register chain into several smaller chain, each connected to a dedicated register.
- Route the
weight_strobenet through a global buffer like a Xilinx BUFG or BUFR. This adds a fixed delay to the net but in exchange the signal can then be distributed with low skew to a large number of cells.
We hope you will find this useful. To stay informed about what’s going on at airhdl, please follow us on twitter or on LinkedIn.